
Introduction
En télécommunications et en informatique, un jeu de caractères codés est un code qui associe un jeu de caractères abstraits d’un ou plusieurs systèmes d’écriture (comme des alphabets ou des syllabaires) utilisés pour transcrire des langues naturelles avec une représentation numérique pour chaque caractère de ce jeu, ce nombre pouvant lui-même avoir des représentations numériques différentes. (Source : Wikipédia).
Nous avons vu précédemment comment nous pouvions représenter les nombres en mémoire en utilisant la numération binaire. Pour pouvoir coder un texte, le problème est donc d’associer chaque caractère utilisé à un nombre.
Par exemple, on pourrait représenter la lettre A par 1, la lettre B par 2, etc. Il faudrait aussi associer un nombre à chaque lettre minuscule, à chaque chiffre, à chaque signe de ponctuation.
Historiquement, de nombreux systèmes de codage ont été développés, souvent incompatibles entre eux, ce qui rendait très complexe la communication entre deux machines de constructeurs différents. En 1960, le code ASCII (pour American Standard Code for Information Interchange) est créé pour tenter de standardiser tout cela.
Le code ASCII
Le code ASCII est un code sur 7 bits, permettant donc de coder 27 = 128 caractères. Parmi eux, 33 sont des caractères de contrôle (les caractères ayant un code de 0 à 31, ainsi que le caractère de code 127), ce qui ne laisse la place que pour 95 caractères dits imprimables : les lettres majuscules, les lettres minuscules, les chiffres et quelques symboles et signes de ponctuation. Il n'y a par contre pas assez de place pour coder les lettres accentuées ou d'autres symboles. Le huitième bit le plus à gauche sera toujours à zéro. Un caractère est donc codé sur 8 bits, soit un octet. Le tableau de correspondance entre nombre et caractère est le suivant : (cliquer sur le tableau pour l'agrandir).
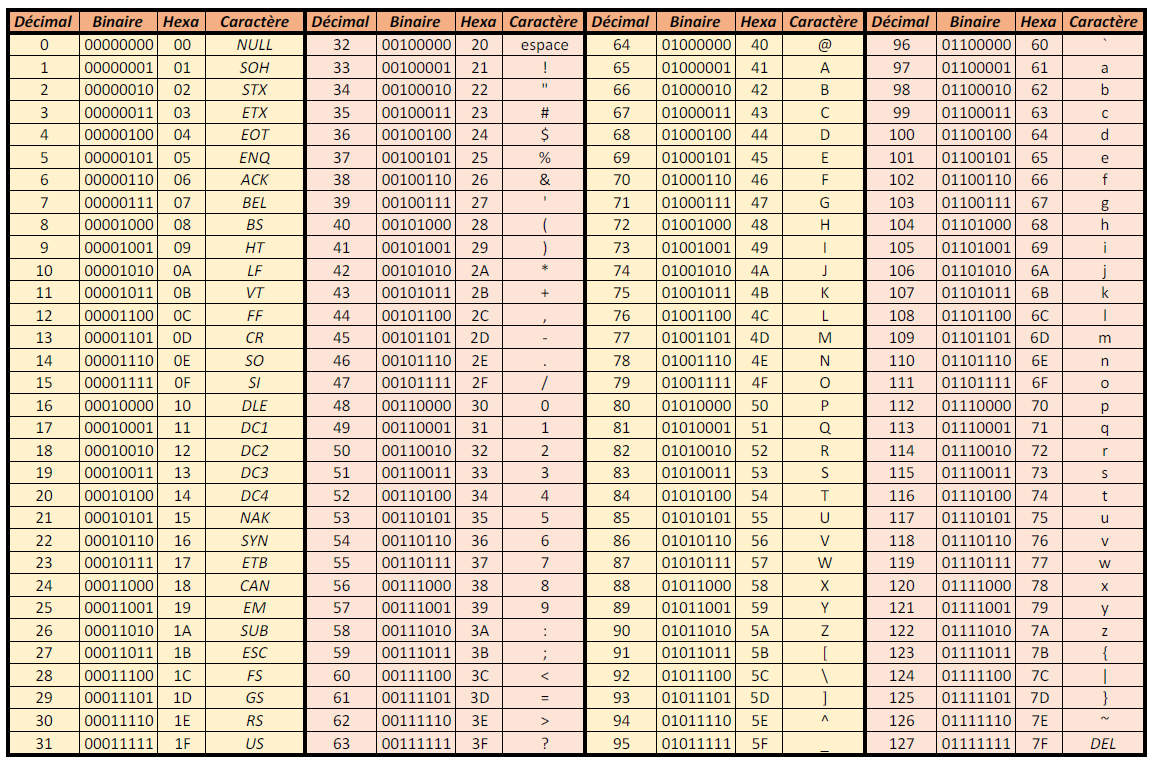
Exercices :
- Quel est le texte codé en ASCII par la séquence de bits suivante :
01001110 01010011 01001001 00100000 00100001 - Codez en ASCII binaire la chaîne : Nous sommes en 2019
- Peut-on coder en ASCII binaire la chaîne : Les ânes paissent dans les prés. ? Justifier.
Solutions :
NSI !01001110 01101111 01110101 01110011 00100000 01110011 01101111 01101101 01101101 01100101 01110011 00100000 01100101 01101110 00100000 00110010 00110000 00110001 00111001- On ne peut pas coder la chaîne en ASCII car il n'y a pas de codes pour les caractères â et é
Remarques :
- Nous ne discuterons pas ici du rôle des caractères de contrôle.
- Pour des raisons pratiques, dont nous ne discuterons pas non plus ici, chaque caractère occupe un octet, donc 8 bits. Le code ASCII ne se servant que de 7 bits, il reste donc 1 bit inutilisé, laissé à 0 dans le tableau précédent. Historiquement, dans certains systèmes, ce 8ème bit servait pour détecter certaines erreurs de transmission (bit de parité).
Le Code ASCII a été à l’origine créé pour coder n’importe quel texte en langue anglaise. Les 95 caractères imprimables sont donc tout à fait suffisants. On peut par contre voir que ce n’est pas vrai pour d’autres langues, comme le français, à cause de l’absence des caractères accentuées et de la cédille, notamment (cf. exercice 3). Afin de pouvoir coder des textes utilisant plus de caractères que la langue anglaise, d’autres méthodes de codage ont dû être développées. Plus d'information sur la page Wikipédia correspondante.
La norme ISO 8859-1
La norme ISO 8859-1, aussi appelée « latin 1 » ou « européen occidental », est une méthode de codage sur 8 bits, permettant de coder 28 = 256 caractères, soit deux fois plus que la norme ASCII. Sa première version date de 1986. Pour des raisons de compatibilité, les 128 premiers caractères de la normes ISO 8859-1 sont identiques aux 128 caractères ASCII. Sur les 128 caractères restants, 32 sont inutilisés (codes de 128 à 159), et 2 correspondent à des caractères spéciaux : le code 160 : NBSP (« Non Breakable Space » ou « espace insécable »), et le code 173 : SHY (« Soft Hyphen » ou « tiret de coupure de mot »). Il reste donc 94 caractères imprimables, comportant la plupart des lettres accentuées (en version majuscule et en version minuscule), la cédille, ainsi que d’autres symboles, comme la livre sterling ou le yen. (cliquer sur le tableau suivant pour l'agrandir).
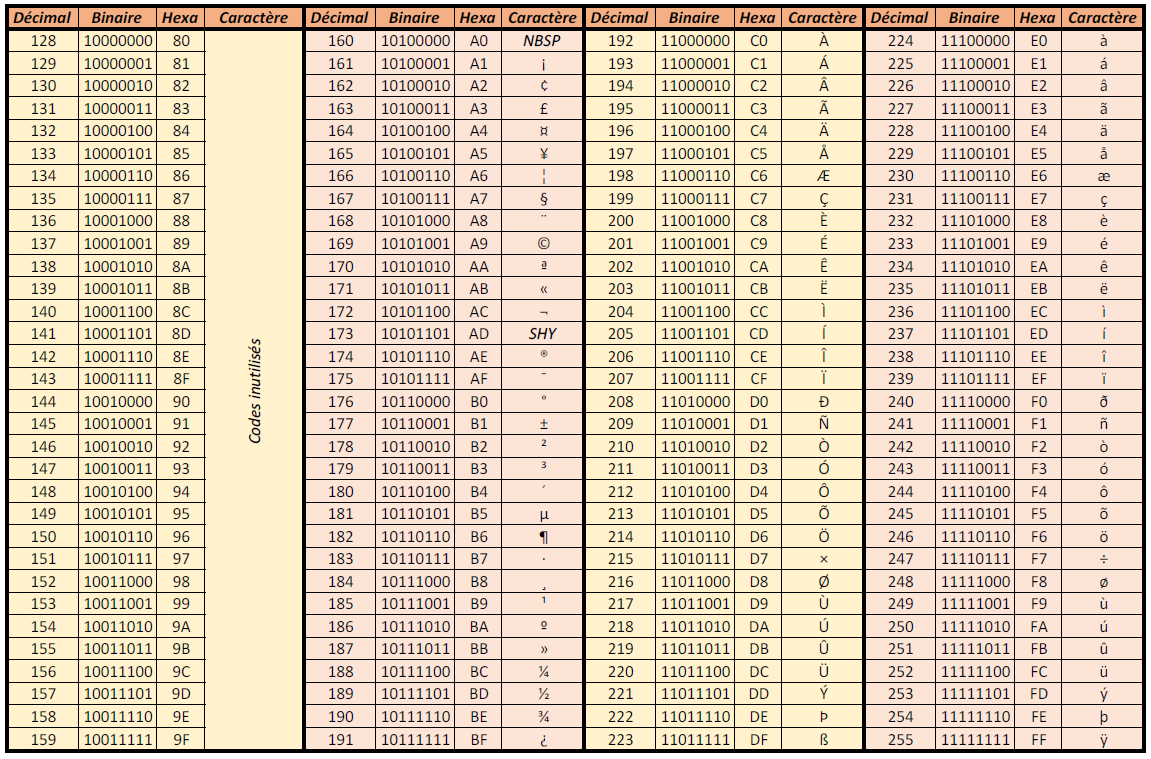
Exercice :
- Peut-on maintenant coder en ISO 8859-1 la chaîne : Les ânes paissent dans les prés. ? Justifier.
Solution :
- On peut maintenant coder la phrase :
01001100 01100101 01110011 00100000 11100010 01101110 01100101 01110011 00100000 01110000 01100001 01101001 01110011 01110011 01100101 01101110 01110100 00100000 01100100 01100001 01101110 01110011 00100000 01101100 01100101 01110011 00100000 01110000 01110010 11101001 01110011 00101110
Ce système n’est pas encore parfait :
- Il ne permet pas de coder tous les caractères de toutes les langues européennes. Notamment, il manque les caractères oe et OE utilisés en français.
- Les caractères inventés après 1986 (comme par exemple le symbole « euro » : €) ne sont bien évidemment pas présents.
Pour régler ces problèmes, la norme 8859 se décline en plusieurs parties, chacune correspondant à une langue ou à un groupe de langues donné. Vous pourrez trouver plus d’informations sur la page Wikipédia correspondante. On peut citer par exemple la norme 8859-15, parfois appelée « latin 9 », inventée en 1998, reprend la quasi intégralité de la norme 8859-1, en remplaçant quelques caractères peu utilisés par des nouveaux, notamment €, OE et oe. Cette norme a tendance à remplacer la norme 8859-1.
Il reste des problèmes assez ennuyeux alors que les échanges de données deviennent de plus en plus internationaux :
- Si un fichier a été codé avec une des normes 8859, on obtiendra un résultat différent si on le décode avec une norme différente. Voir à ce propos le tableau présent sur Wikipédia.
- Certaines langues, comme le chinois ou le japonais comportent un très grand nombre de glyphes, supérieur à 256, ce qui rend impossible un codage sur seulement 8 bits.
Pour toutes ces raisons, une nouvelle méthode de codage s’est vite imposée afin de standardiser le codage de l’information au niveau mondial.
Unicode et UTF-8
La première version du système Unicode a été créée en 1991. Ce système code les caractères sur plus de 16 bits, ce qui permet plus de 216 = 65 536 caractères différents. On en est actuellement à plus de 130 000 symboles. On a ainsi accès à toutes les lettres de tous les alphabets existants, à tous les glyphes ou idéogrammes possibles, tous les symboles mathématiques existants, et même un très grand nombre de pictogrammes et d’emojis.
Le problème de coder les caractères avec plus de 16 bits, et que la taille du texte va plus que doubler par rapport à un texte codé en ASCII, ce qui peut être très pénalisant pour de très grands textes. L’encodage UTF-8 (Universal Character Set Transformation Format - 8 bits) est une méthode de codage à taille variable, où un caractère donné va être codé par une séquence d’un à quatre octets, de la façon suivante :

Lorsque le premier bit est à 0, on sait que le caractère n’est codé que par un seul octet. Si le premier bit est à 1, le nombre de bits à 1 qui suivent indique sur combien d’octets le caractère est codé. Un gros avantage de ce système d’encodage est qu’il est totalement compatible avec le code ASCII. L’inconvénient est que certains caractères seront codés sur plusieurs octets. Ce système permet théoriquement de coder 221 = 2 097 152 caractères maximum. Il existe d’autres méthodes d’encodage, comme UTF-16 et UTF-32. Ces méthodes ne seront pas étudiées ici. Plus d'informations sur Unicode et sur UTF-8.
Exercices :
- En utilisant le site : https://unicode-table.com/fr/#control-character , traduire en UTF-8 binaire le mot suivant : Élève. Combien faut-il d’octets pour coder ce mot ? Combien en faudrait-il pour coder ce mot en utilisant ISO 8859-1 ?
- Quel est le mot codé par cette séquence UTF-8 :
01000001 01110000 01110010 11000011 10101000 01110011? - Si on considère que la séquence de bits précédentes code maintenant un texte en utilisant la norme ISO 8859-1, quel mot obtient-on ? Avez-vous déjà remarqué ce phénomène ? Si oui, à quelle occasion ?
Solutions :
11000011 10001001 01101100 11000011 10101000 01110110 01100101. Il faut 7 octets pour coder le message, alors qu'avec la norme ISO 8859-1, il n'en faudrait que 5, car il y a 5 caractères.- Après
- Après : Le caractère è est codé par 2 octets en UTF-8, et ces 2 octets vont avoir une signification particulière dans la norme ISO 8859-1. Vous avez peut-être déjà remarqué ce phénomène sur certaines pages web mal codées, où les lettres accentuées sont remplacées par des séquences de caractères "bizarres".