
Principe de l'algorithme
Nous avons vu précédemment l'algorithme naïf permettant de chercher un élément dans une liste. Nous allons maintenant partir d'une liste comportant N éléments triés :

Le principe de la recherche par dichotomie est le suivant : supposons que nous voulions savoir si le nombre 25 est présent dans la liste. On repère, à l'aide de trois pointeurs (trois variables), les positions du début, de la fin et du milieu de la liste. Dans notre exemple :
début = 0, fin = 10 et milieu = ( 0 + 10 ) // 2 = 5
(On utilise la division entière // car un indice de liste doit être forcément un nombre entier).
On regarde ensuite si la valeur du tableau à l'indice milieu est égal à l'élément cherché :
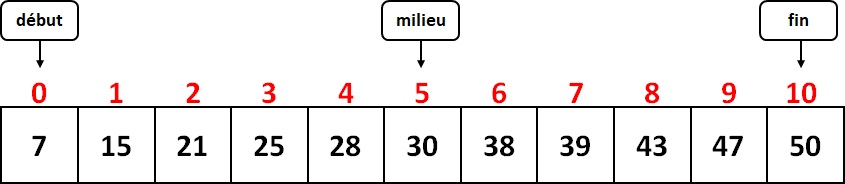
Ici tableau[milieu] = 30. 30 étant plus grand que 25 et le tableau étant trié, on peut donc en déduire que l'élément cherché, s'il est présent, se situe à gauche de la position d'indice milieu. On peut donc limiter la recherche à la moitié gauche du tableau. On déplace donc le pointeur fin(que l'on place à la position milieu - 1), et on calcule la nouvelle position de milieu:
milieu = (début + fin) // 2 = (0 + 4) // 2 = 2
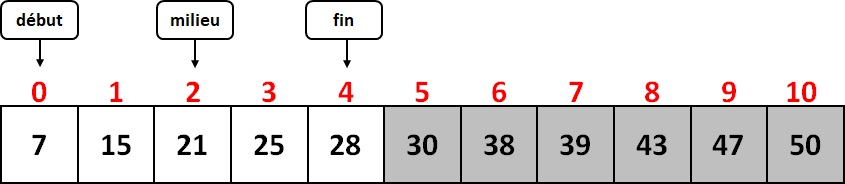
On regarde ensuite si la valeur du tableau à l'indice milieu est égal à l'élément cherché : ici tableau[milieu] = 21. 21 étant plus petit que 25, on peut donc en déduire que l'élément cherché, s'il est bien présent, se trouve à droite de la position d'indice milieu. On déplace donc le pointeur début (que l'on place à la position milieu + 1), et on calcule la nouvelle valeur de milieu:
milieu = (début + fin) // 2 = (3 + 4) // 2 = 3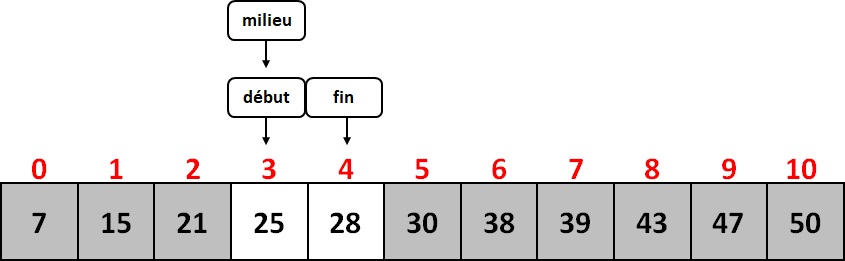
On regarde ensuite si la valeur du tableau à l'indice milieu est égal à l'élément cherché : ici tableau[milieu] = 25. On a trouvé l'élément cherché !
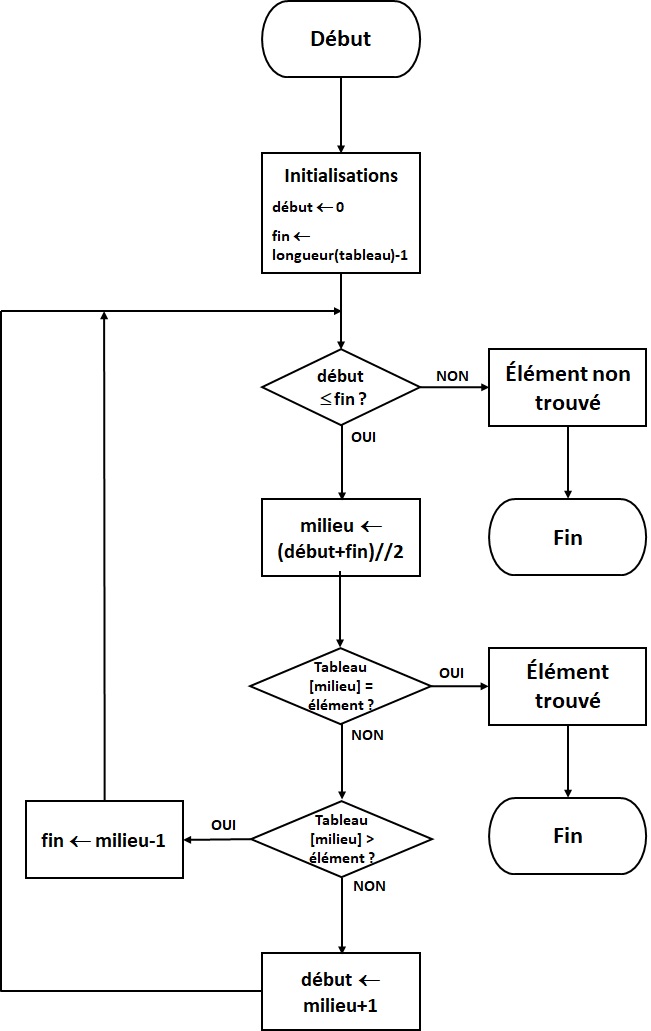
L'organigramme correspondant à l'algorithme précédent est le suivant :
Exercices :
- Pour bien comprendre le fonctionnement de l'algorithme, tester à la main la recherche du nombre 47 dans la liste.
- Essayer ensuite avec un élément non présent dans la liste, comme par exemple 42.
- Dans les deux cas précédents, déterminer le nombre de comparaisons que vous avez faire au total. Comparer ce résultat au nombre de comparaisons qu'il faudrait faire avec l'algorithme naïf.
- Ecrire une fonction Python recherche_dicho(tableau, element) implémentant cet algorithme.
Complexité
Le principe de base de l'algorithme est de découper le tableau en deux jusqu'à ce que les pointeurs début et fin se rejoignent.
Au début de l'algorithme, la taille de la zone de recherche est \( N \), avec \( N \) la taille du tableau.
Au bout d'une étape, la taille de la zone de recherche est de \( \frac{N}{2} \)
Au bout de deux étapes, la taille de la zone de recherche est de \( \frac{N}{4} \)
Au bout de trois étapes, la taille de la zone de recherche est de \( \frac{N}{8} \)
...
Au bout de \( n \) étapes, la taille de la zone de recherche est de \( \frac{N}{2^{n}} \)
L'algorithme s'arrêtera dans le pire des cas lorsque la taille de la zone de recherche sera égale à 1. Il y aura alors deux cas de figure : l'unique élément restant est l'élément recherché, ou c e n'est pas le cas. On peut donc déterminer le nombre \( n \) d'étapes qu'il faudra à l'algorithme pour arriver au résultat dans le pire des cas :
\( \frac{N}{2^{n}}=1 \) donc : \( 2^{n}=N \) càd : \( \ln\left( 2^{n} \right)=\ln\left( N \right) \)
D'où : \( n\times \ln\left( 2 \right)=\ln\left( N \right) \) soit : \( n=\frac{\ln\left( N \right)}{\ln\left( 2 \right)} \)
On définit le logarithme en base 2 de la façon suivante : \( \log_{2}\left( x \right)=\frac{\ln\left( x \right)}{\ln\left( 2 \right)} \)
On a donc : \( n=\log_{2}\left( N \right) \)
On peut donc dire que, dans le pire des cas, la complexité de cet algorithme est en O(log2(N)). On dit aussi que le coût de l'algorithme est logarithmique. On peut comparer ce coût à celui de l'algorithme naïf qui est lui linéaire.
Pour des très grandes valeurs de N, la recherche dichotomique sera donc beaucoup plus rapide que la recherche naïve comme le montre le graphique suivant :
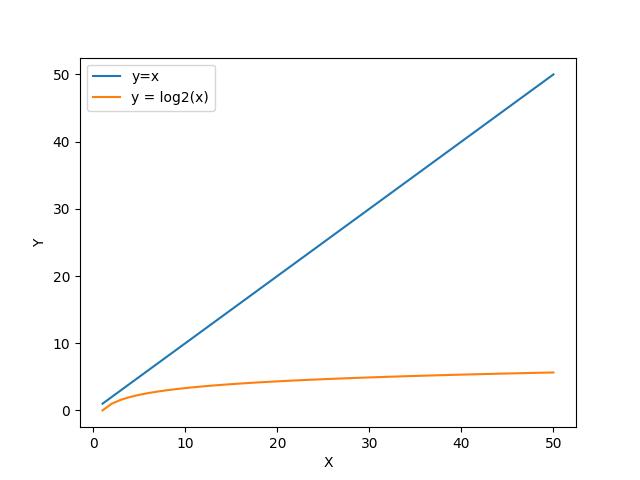
Attention cependant : le gain d'efficacité vient du fait que la liste dans laquelle on fait la recherche est triée. Si les données de départ ne sont pas triées, il faudra rajouter le coût de l'algorithme de tri permettant de mettre les données en forme.
