
Introduction
Trier une liste, c’est mettre tous les éléments de cette liste dans l’ordre, du plus petit au plus grand (ou dans l’ordre inverse, le problème est similaire) sachant qu’initialement les éléments de la liste peuvent être dans un ordre totalement aléatoire. Ce problème qui semble purement mathématique à première vue a de très nombreuses applications pratiques : une université voudra par exemple classer dans l’ordre de leurs résultats les candidats à un concours. L’algorithme PageRank du moteur de recherche Google va classer les pages web en fonction de leur popularité (i.e. nombre de visites) afin de présenter les plus populaires en premier.
Dans cette activité, on ne s’intéressera qu’au tri d’une liste de nombres. On part donc d’une liste du type : [ 4, 2, 5, 1, 3 ]. Par quelle(s) méthode(s) peut-on obtenir la liste triée : [ 1, 2, 3, 4, 5 ] ?
Activité de découverte
Soit le plateau de "jeu" suivant :
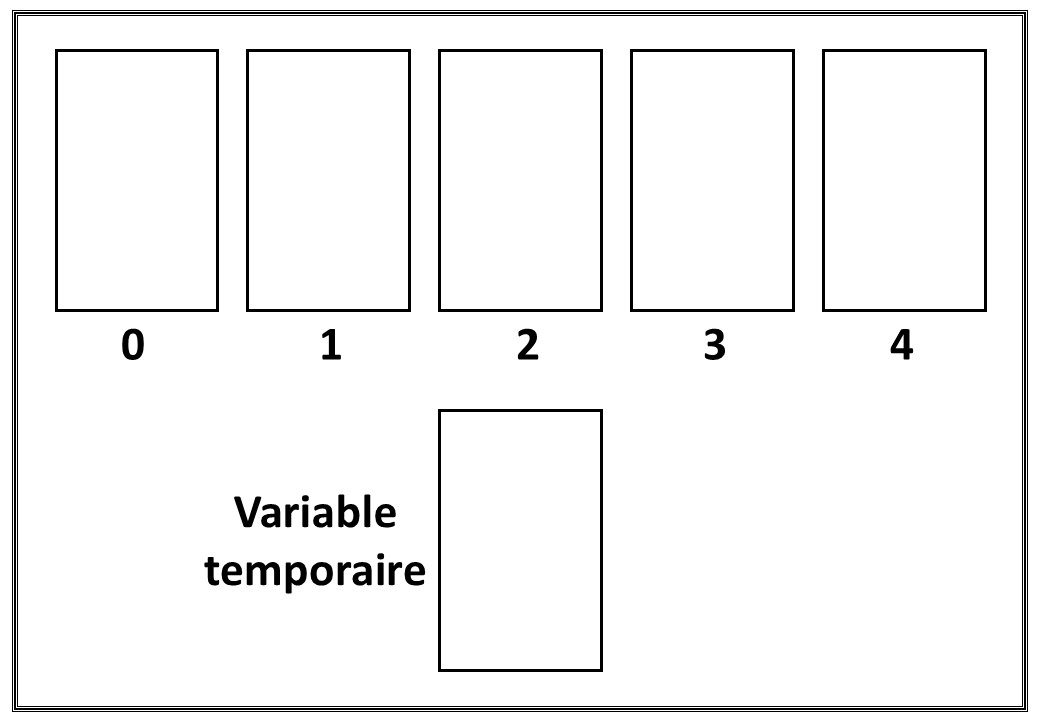
On dispose de cinq cartes numérotées de 1 à 5. La première étape est de placer les cinq cartes dans le désordre dans les emplacements numérotés de 0 à 4 sur le plateau. Le but est de chercher une méthode rationnelle permettant de trier les cinq cartes en utilisant seulement les actions suivantes :
- On peut comparer la valeur de deux cartes quelconques.
- On peut échanger deux cartes, en se servant éventuellement de l'emplacement "Variable temporaire".
Attention : il est important dans cette activité de vraiment se mettre à la place de l'ordinateur, qui n'a pas une vue d'ensemble de toutes les cartes, et qui peut seulement les examiner une par une.
Vous trouverez les fichiers du jeu à télécharger en suivant ce lien.

Tri par insertion
Commencer par visionner la vidéo suivante :
Le principe de ce tri est le suivant :
- On commence par le deuxième élément de la liste. On le compare avec l’élément qui le précède (le premier en l’occurrence). Si les deux éléments sont correctement ordonnés entre eux, on passe à l’étape suivante, sinon on les échange.
- On considère le troisième élément de la liste. On le compare avec l’élément qui le précède (le deuxième). Si les deux éléments sont correctement ordonnés entre eux, on passe à l’étape suivante, sinon on les échange et on fait la même chose pour le deuxième élément et celui qui le précède.
- Etc…
L’algorithme est donc le suivant :
pour i allant de 1 à (longueur de liste – 1)
j ← i – 1
tant que j >= 0 et que liste[j] > liste[j + 1]
échanger liste[j] et liste[j+1]
j ← j – 1
fin tant que
fin pour Exercices :
1./ En partant de la liste donnée en exemple [ 4, 2, 5, 1, 3 ], faire tourner l’algorithme à la main. (Attention de bien donner l’état de la liste à chaque étape).
2./ Créer une fonction Python tri_insertion(liste) qui implémente cet algorithme.
3./ Justifier la terminaison de cet algorithme (c'est-à-dire le fait qu'il se termine bien et ne part pas dans une boucle infinie).
Étude sommaire de la complexité de cet algorithme :
On étudiera ici la complexité en se plaçant dans le pire des cas (liste ordonnée à l’envers). Dans ce cas, lorsqu’on étudie l’élément numéro i, il y a (i – 1) comparaisons à faire. Puisqu’on doit étudier (n – 1) éléments, avec n le nombre d’éléments de la liste, le nombre total de comparaisons est :
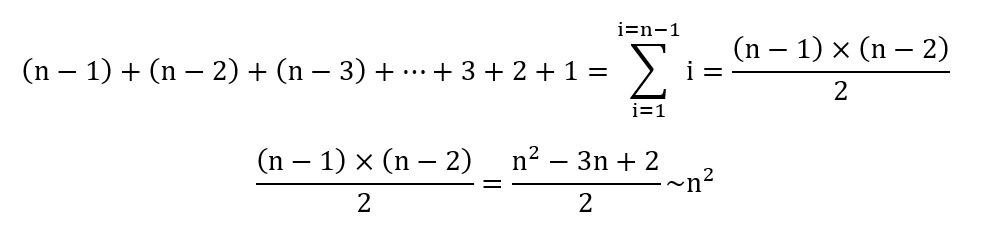
La complexité de l’algorithme est, au pire, en O(n2). On dit aussi que le coût de l’algorithme est quadratique dans le pire des cas.
Tri par sélection
Commencez par visionner la vidéo suivante :
Le principe de ce tri est le suivant :
- On place dans la variable min le nombre 0, qui correspond au rang du premier élément de la liste.
- On parcourt ensuite la liste du deuxième élément jusqu’au dernier. Si on trouve un élément plus petit que l’élément de rang « min », on place le numéro de son rang dans la variable min.
- A la sortie de la boucle, la variable min contient donc le rang du plus petit élément de la liste. On échange cet élément et le premier élément de la liste.
- On recommence cet algorithme en considérant la liste privée de son premier élément.
- Etc…
L’algorithme est donc le suivant :
pour i allant de 0 à (longueur de liste – 2)
min ← i
pour j allant de i + 1 à (longueur de liste – 1)
si liste[j] < liste[min] alors
min ← j
fin si
si min ≠ i alors
échanger liste[min] et liste[i]
fin si
fin pour Exercices :
4./ En partant de la liste donnée en exemple [ 4, 2, 5, 1, 3 ], faire tourner l’algorithme à la main. (Attention de bien donner l’état de la liste à chaque étape).
5./ Créer une fonction Python tri_selection(liste) qui implémente cet algorithme.
6./ Justifier la terminaison de cet algorithme.
Étude sommaire de la complexité de cet algorithme :
Le premier élément de la liste est comparé aux (n – 1) autres, n étant le nombre d’éléments de la liste. Le deuxième est comparé aux (n – 2) suivants. L’élément numéro i sera comparé à (n – i) éléments. Le nombre total de comparaisons est :
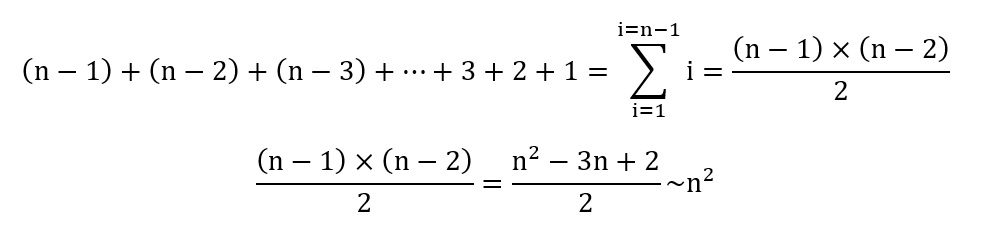
La complexité de l’algorithme est, au pire, en O(n2). On dit aussi que le coût de l’algorithme est quadratique dans le pire des cas.
Pour aller plus loin
Une complexité en O(n2), ou quadratique, veut dire que lorsqu’on multiplie le nombre d’éléments de la liste par N, le nombre d’opérations est multiplié par N2. Le nombre d’opérations, et donc le temps de calcul peut donc devenir très grand pour de grandes listes à trier. Il existe d’autres types d’algorithmes de tri, certains étant plus efficaces, avec une complexité en O(n × log n).
Vous pourrez trouver les simulations de différents algorithmes de tris (dont les deux vus précédemment) sur le site suivant : http://lwh.free.fr/pages/algo/tri/tri.htm
L’intérêt de ce site est que l’on peut voir l’algorithme écrit dans différents langages (dont le Python) se dérouler au fur et à mesure de la simulation.
Vos remarquerez que les différents tris ont été classés en deux catégories : les tris stables et les tris instables. Cette notion de stabilité d’un tri n’est pas au programme, mais elle n’est pas très complexe et est discutée sur la page suivante : http://lwh.free.fr/pages/algo/tri/stabilite_tri.html
Alors que le but est de trouver des algorithmes de plus en plus efficaces, certains essaient au contraire de trouver des méthodes de tri extrêmement inefficaces : voir par exemple, le tri stupide : https://fr.wikipedia.org/wiki/Tri_stupide
Vous pouvez essayer d’implémenter en Python cet algorithme. Que se passe-t-il si le nombre d’éléments de la liste dépasse quelques unités ?